主题
如何使用Ollama调用大模型API服务
本文旨在指导用户通过在JYGPU极智算平台上部署 Ollama 与常见大语言(LLM)模型 API 服务的完整操作。
💡
Ollama是一款开源的AI模型训练与部署工具,可让用户在本地轻松训练、优化并部署AI模型,支持多种模型架构,还提供简单易用的界面和API接口,助力高效开发与应用。JYGPU提供了标准化的 API 接口,让您能够便捷地通过 API 调用方式访问和使用所有功能。
1、GPU容器实例部署
1.1 打开极智算-算力市场: https://www.jygpu.com/markets,选择【GPU容器实例】
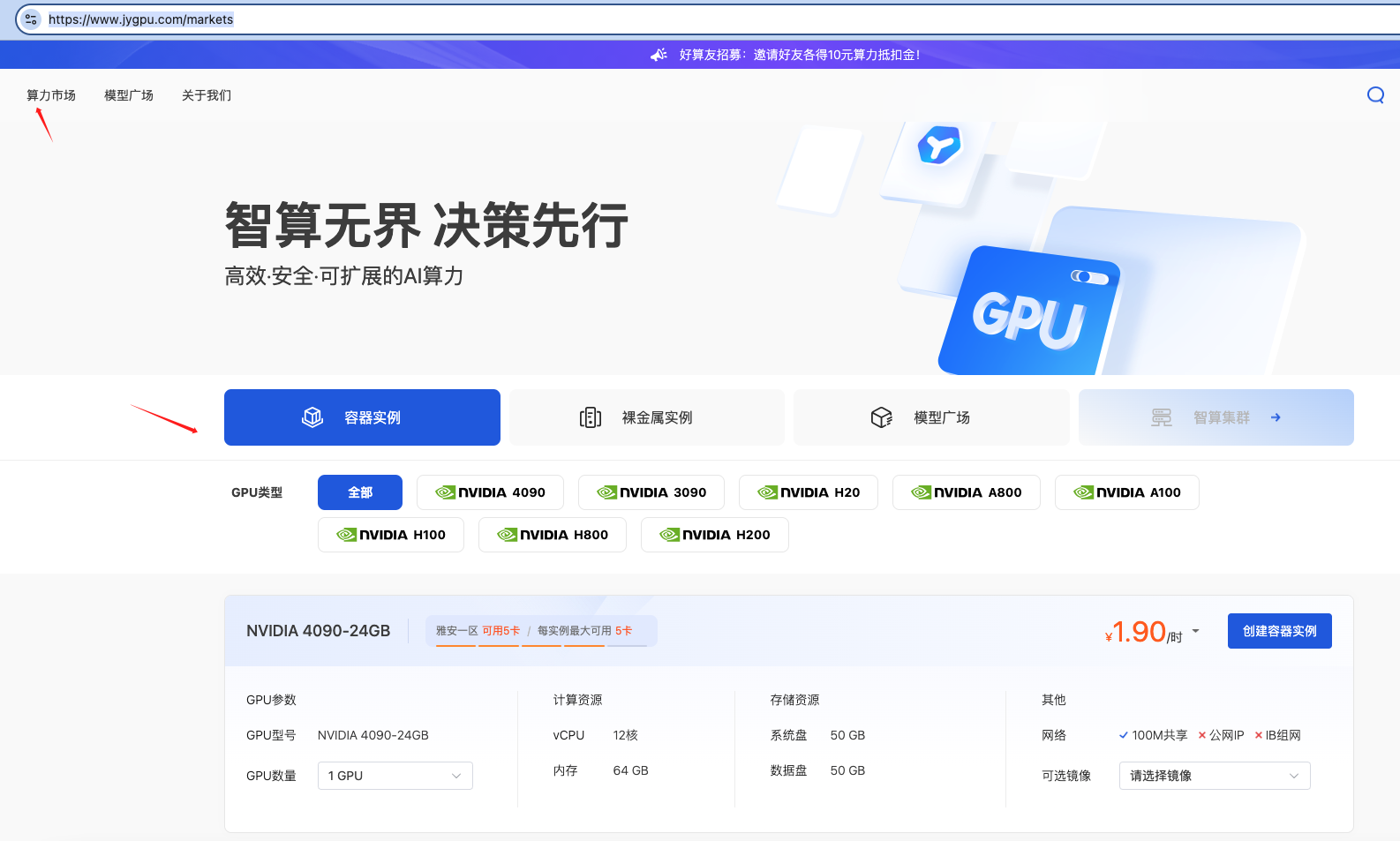
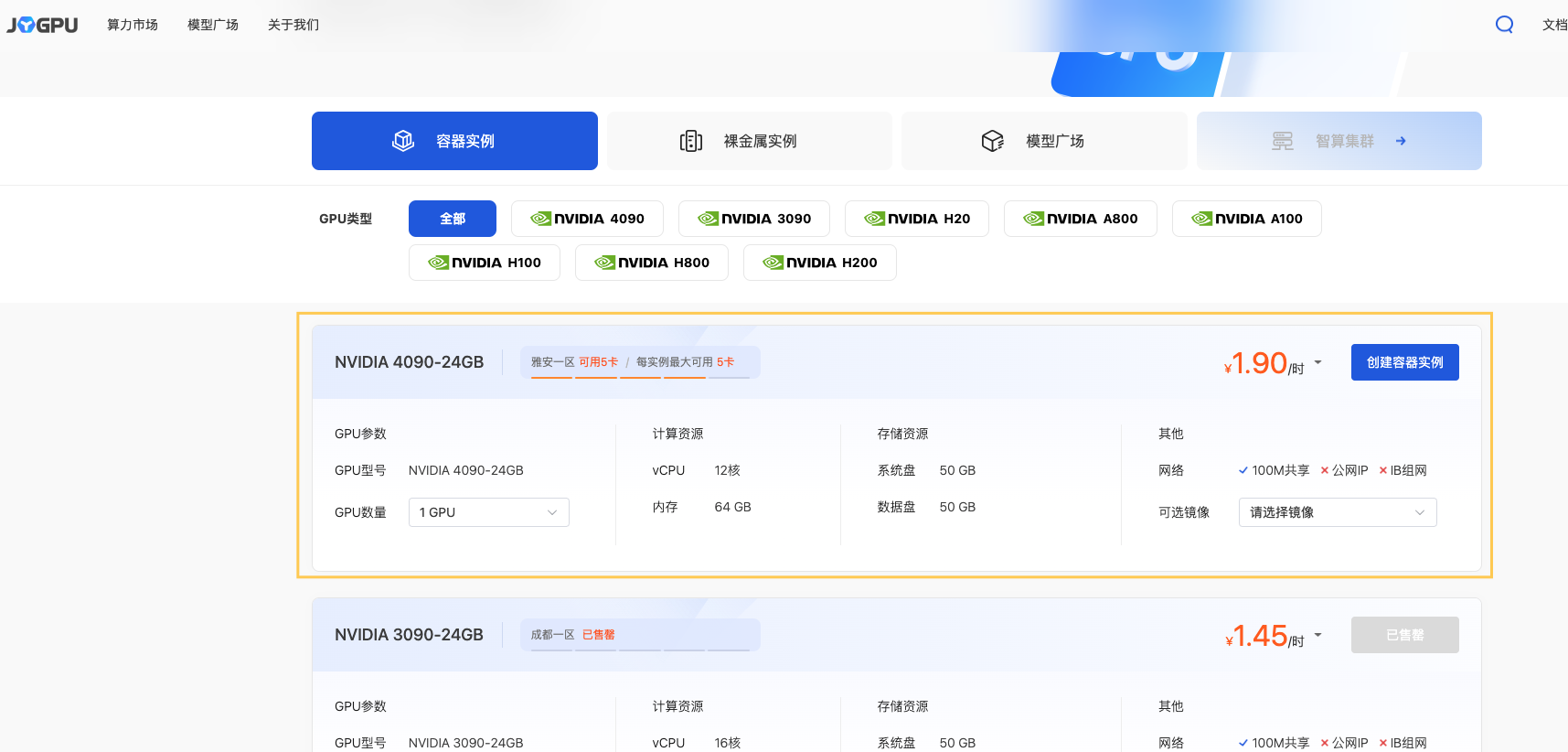
1.2 选择GPU类型
基于自身需要进行配置,参考配置为单卡 4090 。点击【创建容器实例】
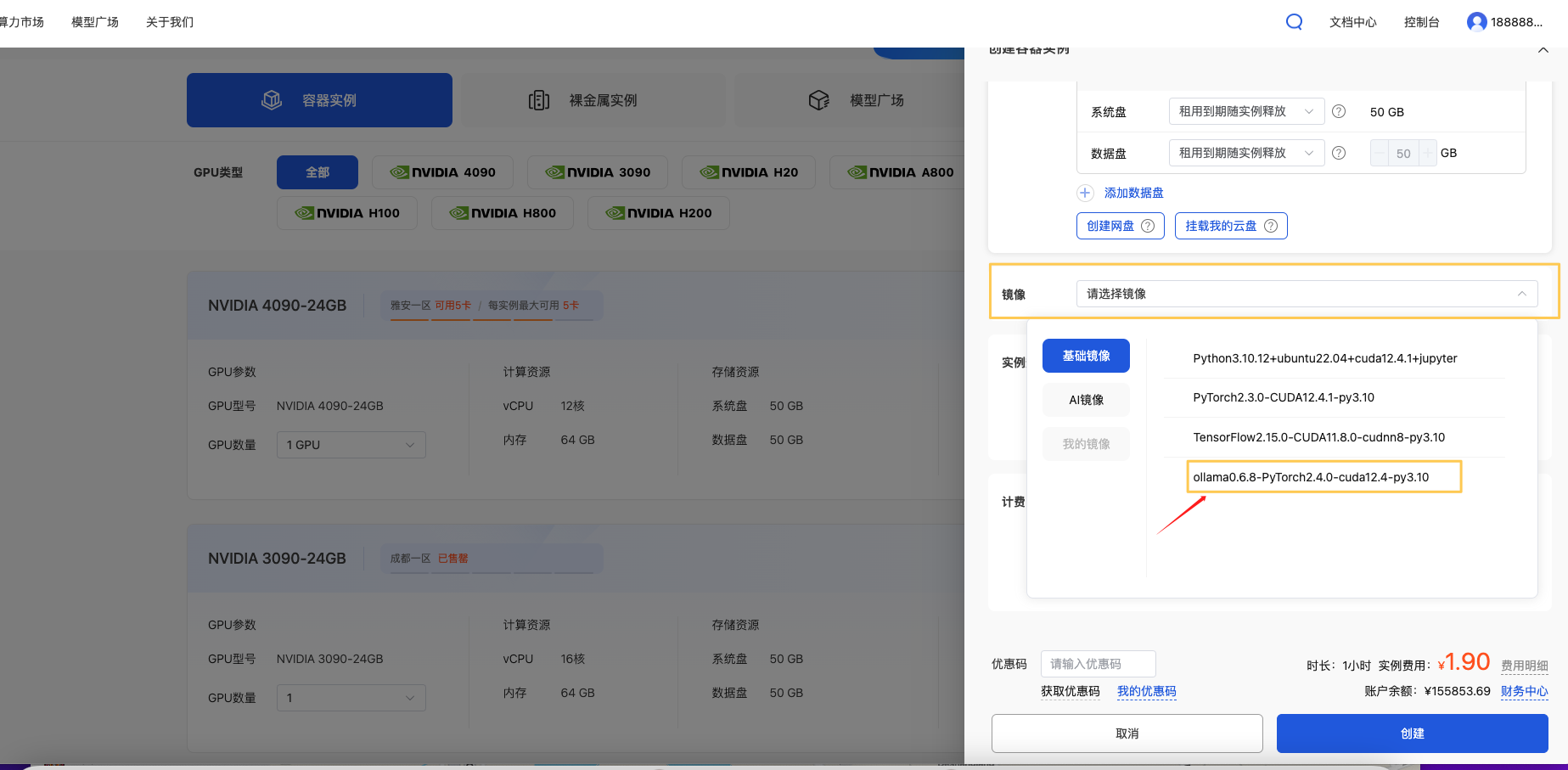
1.3 选择预制Ollama镜像
这里选择 Ollama镜像,点击【创建】。
1.4 耐心等待实例拉取镜像并启动,通常只需要5s-10s
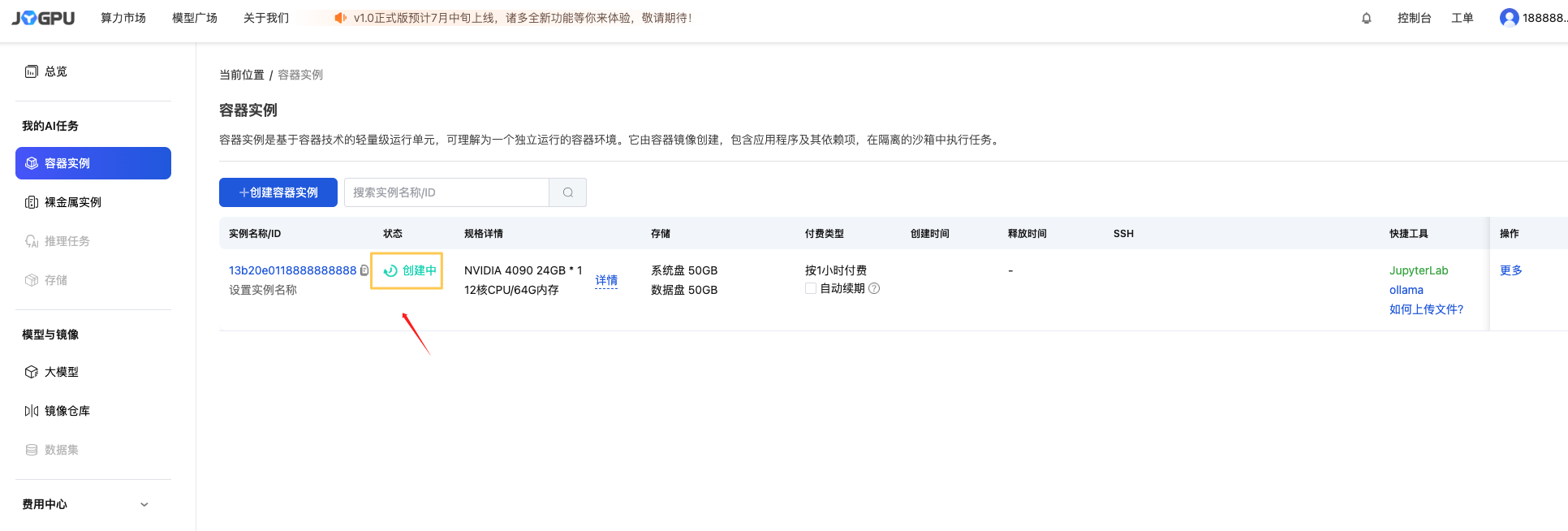
1.5 实例启动完成
在快捷工具出,能看到一个公开访问链接。这个链接就是 Ollama 服务的 API 访问地址。
将这个 API 地址复制下来,就可以在任何支持 Ollama 协议的应用程序中使用。

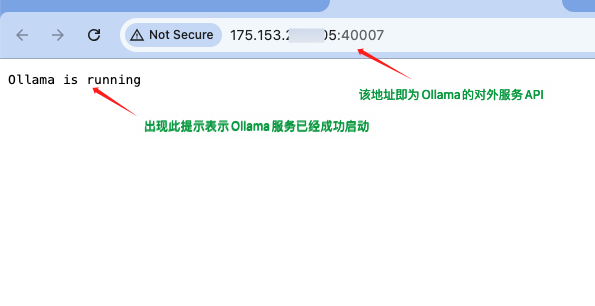
1.6 验证Ollama启动成功
快捷工具栏处点击【Ollama】,就可以看到以下内容,说明Ollama服务部署并运行了。
2、安装所需要的大模型
Ollama 部署完成了,该镜像内未予置任何大模型,您可根据需要安装所需要的模型。
2.1 访问Ollama官网:https://ollama.com,选择【Models】
2.2 搜索您需要的模型,这里以阿里QWEN3为例
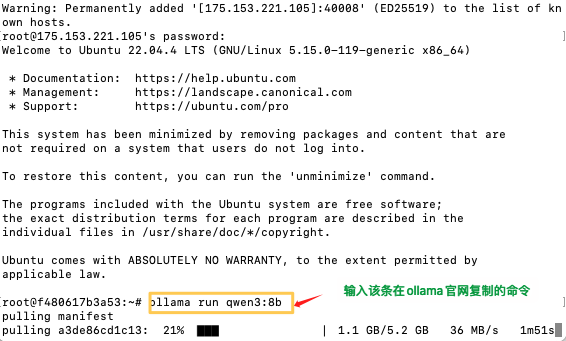
2.3 复制该条命令至刚才启动的容器实例SSH远程连接终端
powershell
ollama run qwen3:8b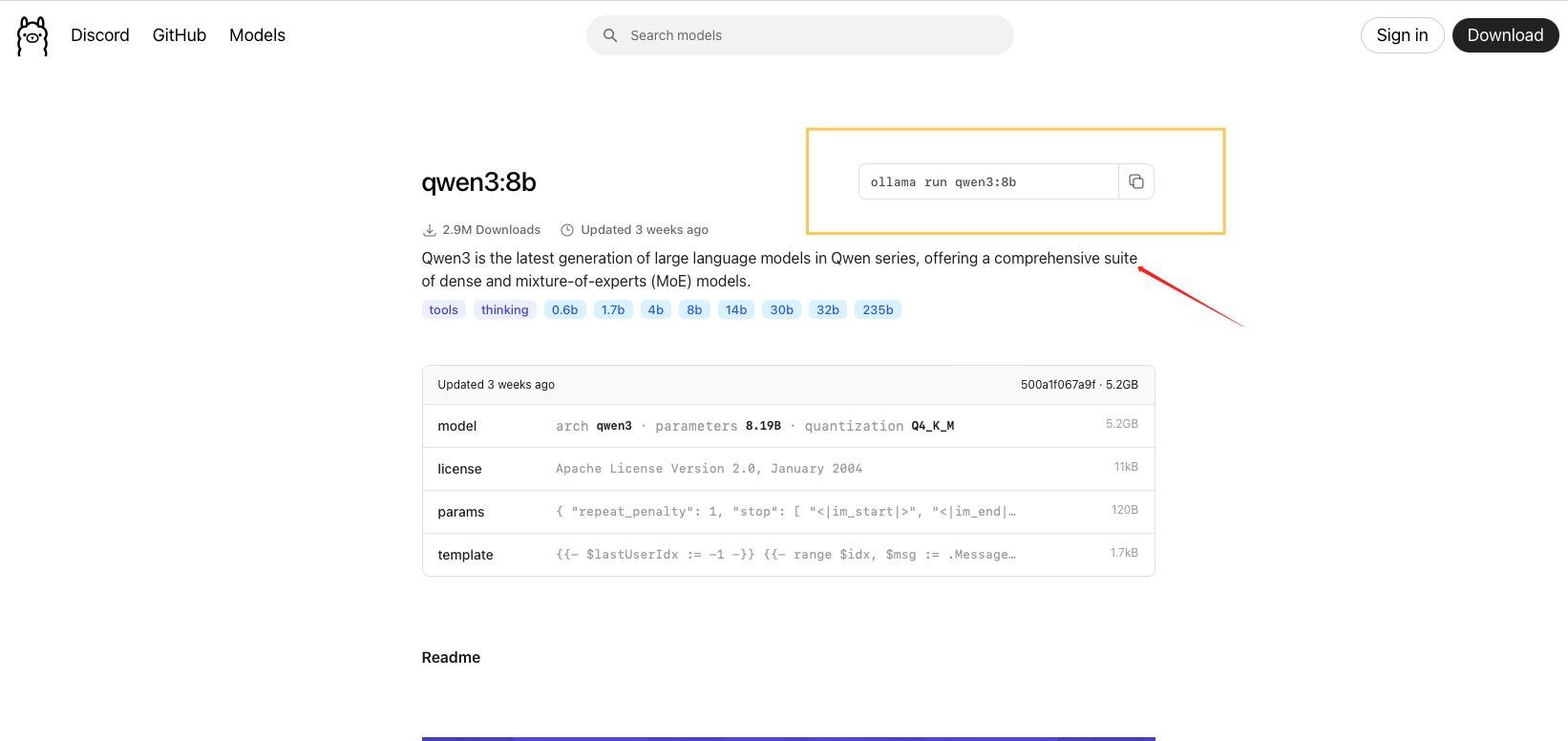
注:容器实例如何进行SSH连接请参考以下文档
https://doc.jygpu.com/guide/ssh-connect.html
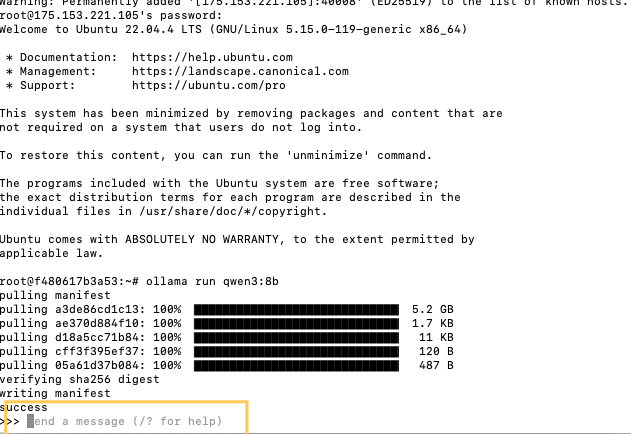
2.4 等待QWEN3模型下载完成
2.5 模型下载完成后,出现该对话界面,表示模型已经部署成功
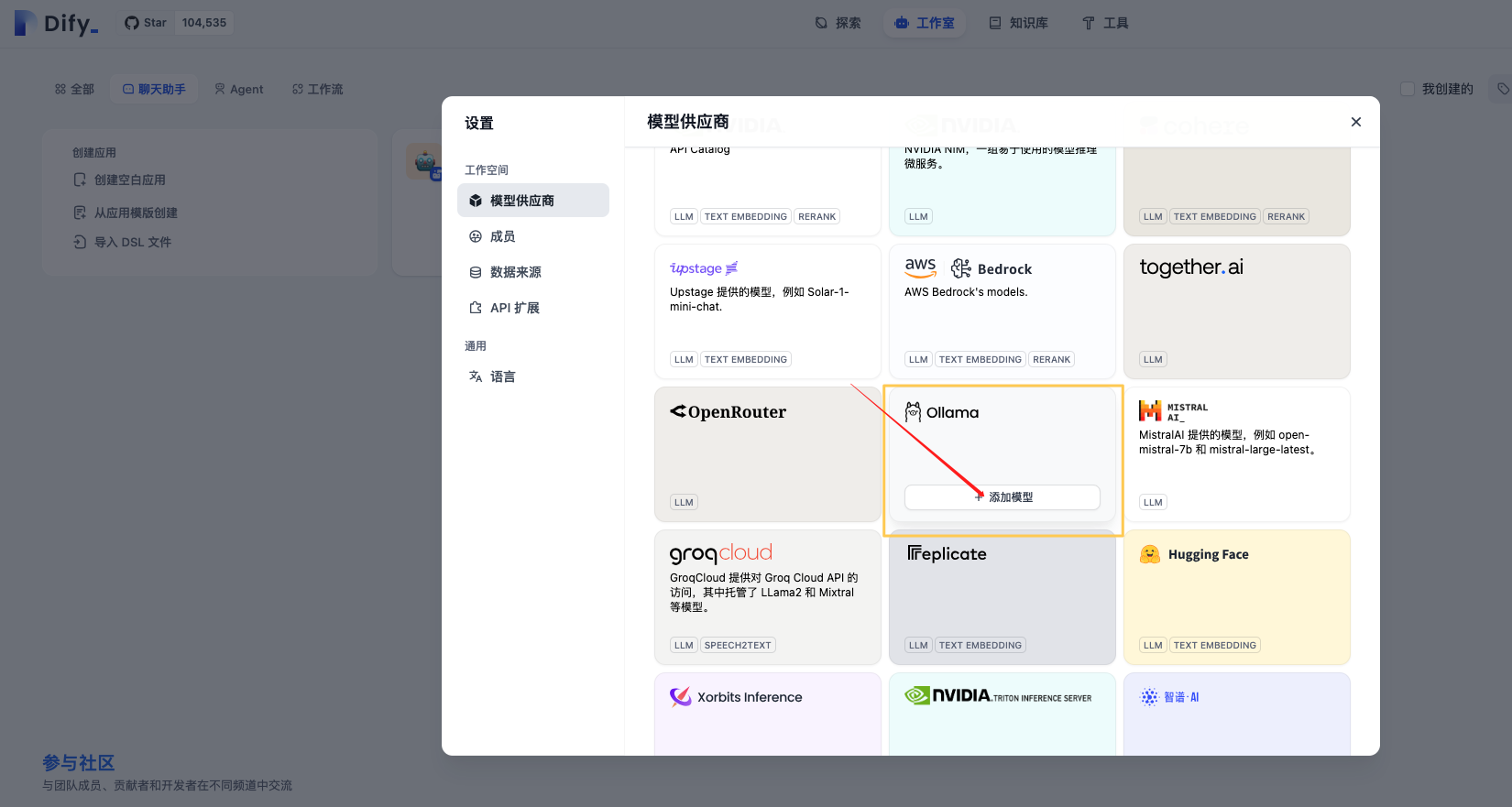
3、在第三方客户端调用该模型API,本文以Dify为例
Dify-【设置】-【模型供应商】-【添加模型】
此处填写在步骤1.6获得的ollama API地址
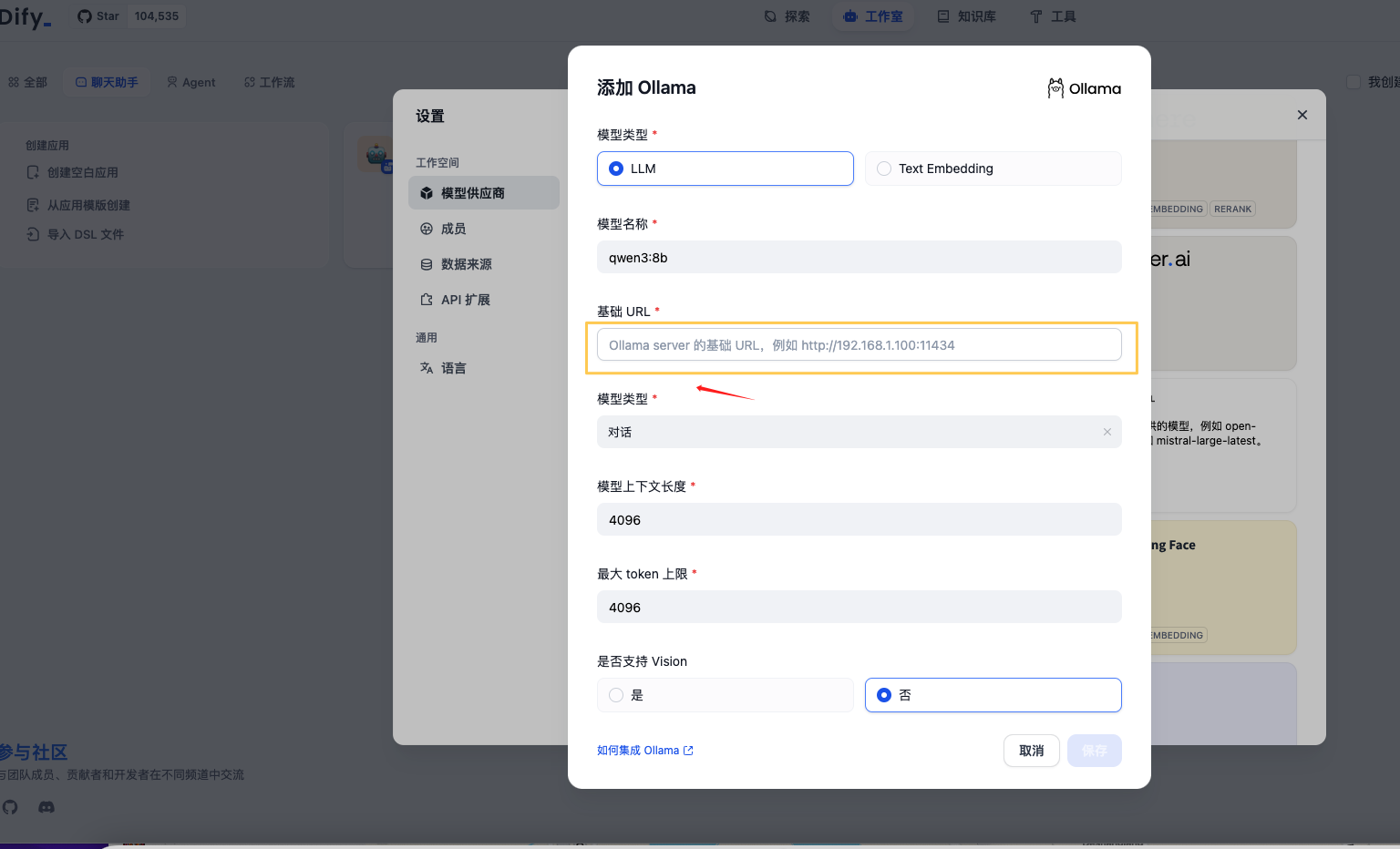
点击【保存】,即可看到模型API已经调用成功
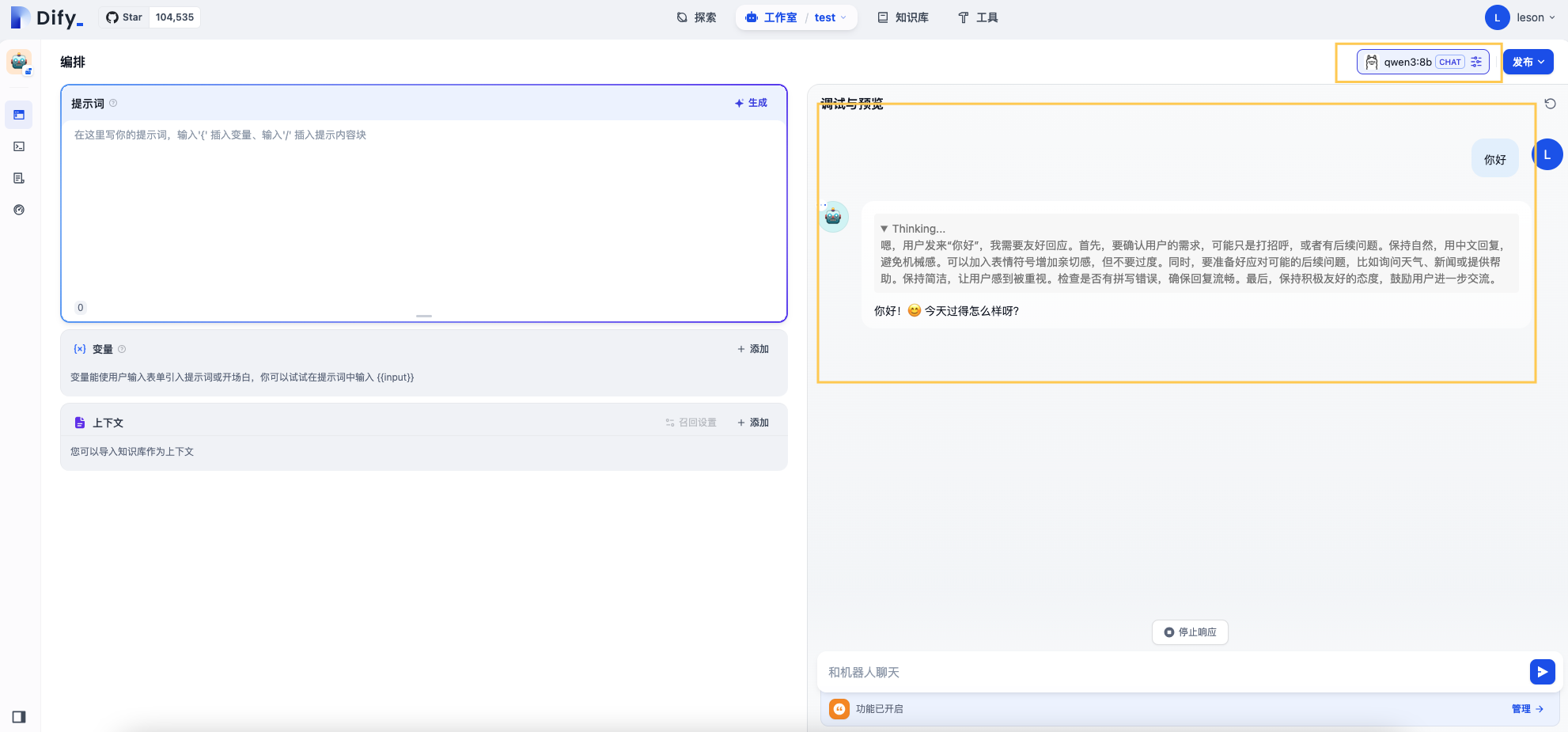
我们在Dify工作区建立一个测试用对话应用,可以看到已经成功调用我们在容器实例部署的qwen3:8b模型,并能提供智能对话服务
注:关于第三方客户端Dify的使用教程请参考网络教程,或咨询客服
3、保存该已经部署好模型的容器镜像
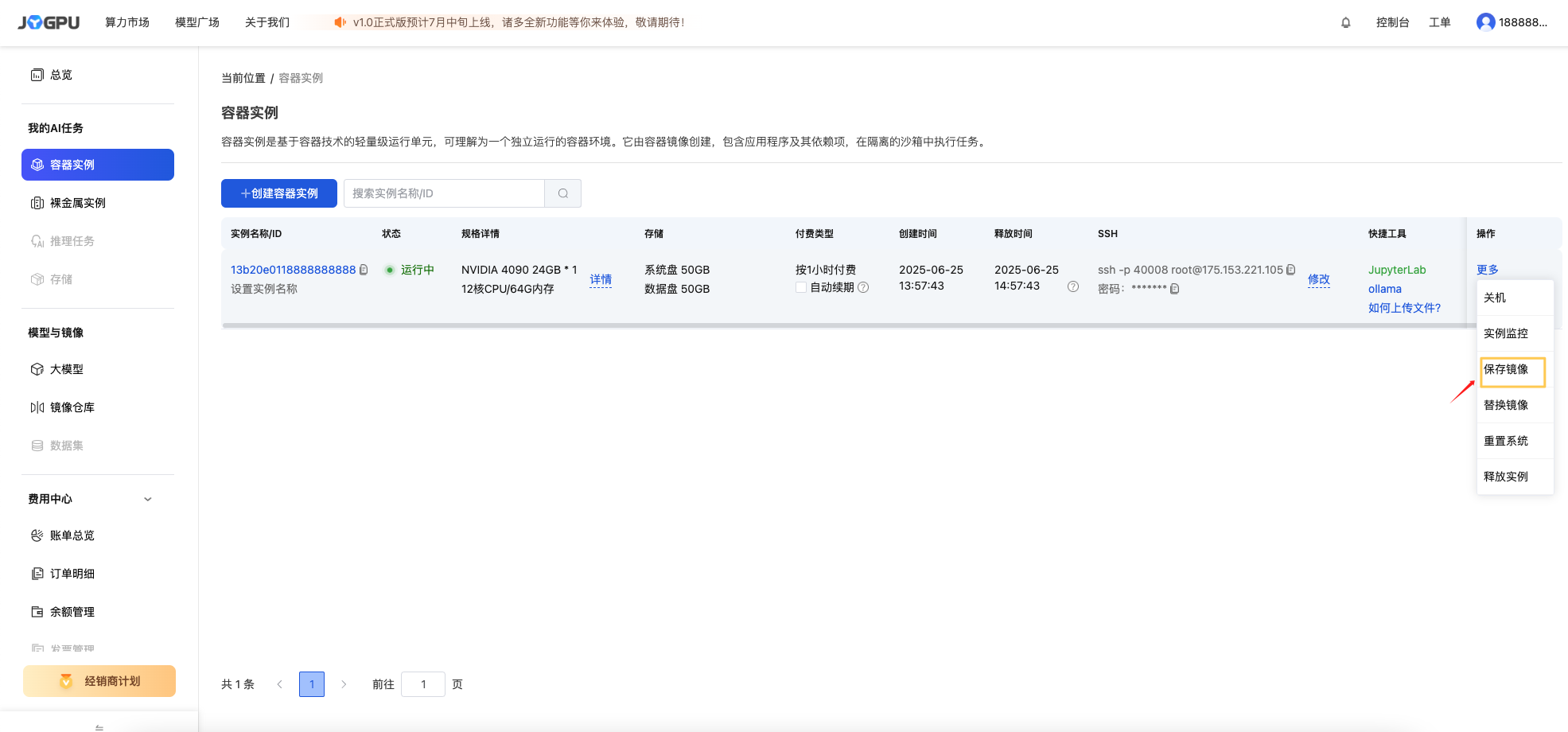
控制台-选择该容器实例-点击【更多】-点击【保存镜像】
镜像保存后,即便该实例释放,在新的实例中您也可以通过选择已保存的镜像再次调用该模型API